Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
Inside AI Minds How Hallucinations Truly Work
Hallucination is one of the most researched topics in AI. Recent studies show we have got it all wrong writes Satyen K Bordoloi.
In 2023 when I asked ChatGPT for the world record for crossing the English Channel on foot its answer which I recorded in a Sify article went viral. It has been quoted in several papers for one simple reason it is one of the clearest examples of what is known in the domain of Machine Learning as hallucinations.
No one is giving digital LSD to AI yet these systems ability to make up crazy things has baffled researchers and sparked their curiosity about the pathway that makes it possible. Now thanks to groundbreaking research from Anthropic we have some answers. And it is stranger than thought itself.
 I tried to make Claude Hallucinate in ways that the researchers succeeded but I did not
I tried to make Claude Hallucinate in ways that the researchers succeeded but I did not
For years the prevailing narrative around the topic has been straightforward language models are trained to predict the next word so they must guess even if they do not know the answer. This has been believed to be the reason why chatbots like ChatGPT sometimes invent facts cite fake papers or fabricate entirely fictional events such as the world record for crossing the English Channel.
However Anthropics landmark research paper On the Biology of a Large Language Model flips this understanding on its head. The truth is far stranger and fascinating than we could have ever thought on our own.
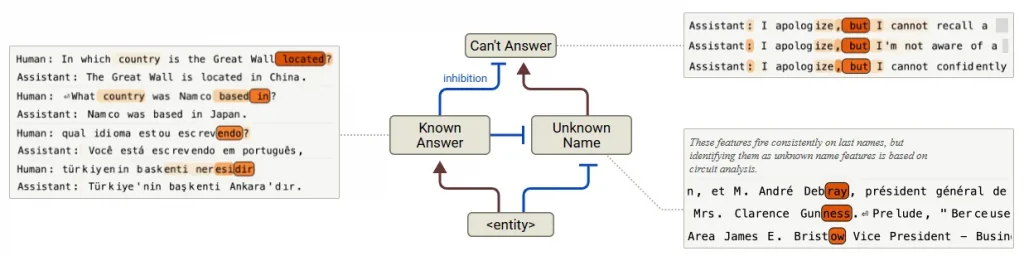 A summary of the key entity recognition mechanisms in Claude (Image Courtesy)
A summary of the key entity recognition mechanisms in Claude (Image Courtesy)
Understanding the Inner Conflict A Sort of Adversarial Network
Contrary to what has been believed AI models in the researchers case Claude 3 5 Haiku are not hardwired to hallucinate. It is the opposite their default behaviour is to refuse to answer questions they are not sure of. Think of it like that cautious classmate from your school days wise yet preferring to stay silent unless she was absolutely sure of the answer. Claude operates in that fashion.
Researchers discovered a built in circuit that activates every single time the model receives a query its sole purpose is to declare I do not know. This launches even when the system is certain of the answer. So when it does not know the path is straightforward like when researchers asked about Michael Batkin a made up name. Claude responded correctly so I cannot find a definitive record of a sports figure named Michael Batkin.
You can call this I can not answer circuit the default factory setting of the AI for everything even familiar names or topics. So how does Claude ever manage to answer anything. To do this it relies on a competing mechanism. When Claude recognises someone familiar such as basketball legend Michael Jordan a separate set of features is activated and overrides this default mode.
These known answer features override the default refusal circuit enabling the model to respond confidently with the correct answer. This tug of war between I do not know and I got this is what determines whether Claude answers a question or declines.
Think of it like GANs Generative Adversarial Networks which are used to train advanced AI systems. The known answer feature and its I do not know circuit are in a constant state of conflict sparring with each other every time a question is asked regardless of whether the system knows the answer or not. In simpler terms you can think of this system like that of a cars brakes and accelerator one stops the other propels and in tandem with both the vehicle propels forward safely.
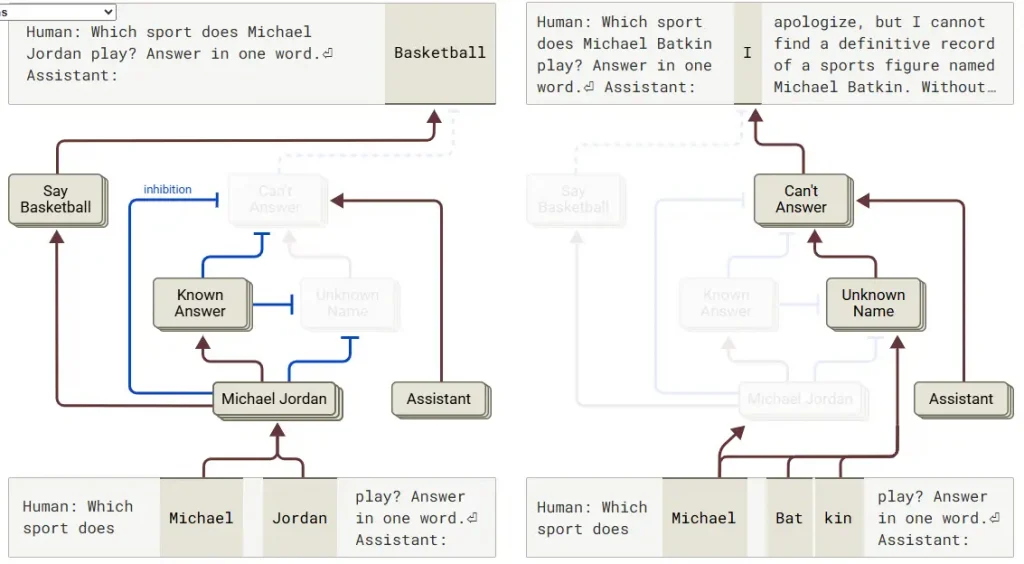 Two simplified attribution groups for Michael Jordan and a fictitious Michael Batkin and the hallucinations it induced (Image Courtesy)
Two simplified attribution groups for Michael Jordan and a fictitious Michael Batkin and the hallucinations it induced (Image Courtesy)
How Do AI Hallucinations Actually Happen
Hallucinations occur when this balance suffers a catastrophic failure for certain types of interactions. To their surprise researchers found that they could force Claude to hallucinate by doing either of these two things artificially activating its known answer features or suppressing its can not answer circuit.
For example when scientists suppressed Claudes refusal pathway and stimulated its known entity features for the fictional Michael Batkin the model confidently hallucinated. Beyond such lab trickery natural misfires also happen. Like when Claude recognises a name but lacks detailed knowledge the known entity circuit may activate weakly overriding the refusal system. The model then fabricates a plausible sounding answer as seen in the case below.
When a researcher asked Name one paper written by Andrej Karpathy Claude responded ImageNet Classification with Deep Convolutional Neural Networks. The only problem is that although that paper is real Karpathy has not co authored it. So why did Claude hallucinate. The model recognised Andrej Karpathy as a known AI researcher activating the known entity circuit but it lacked specific details about his work. Hence instead of refusing it defaulted to a statistically plausible guess tied to his field a classic hallucination.
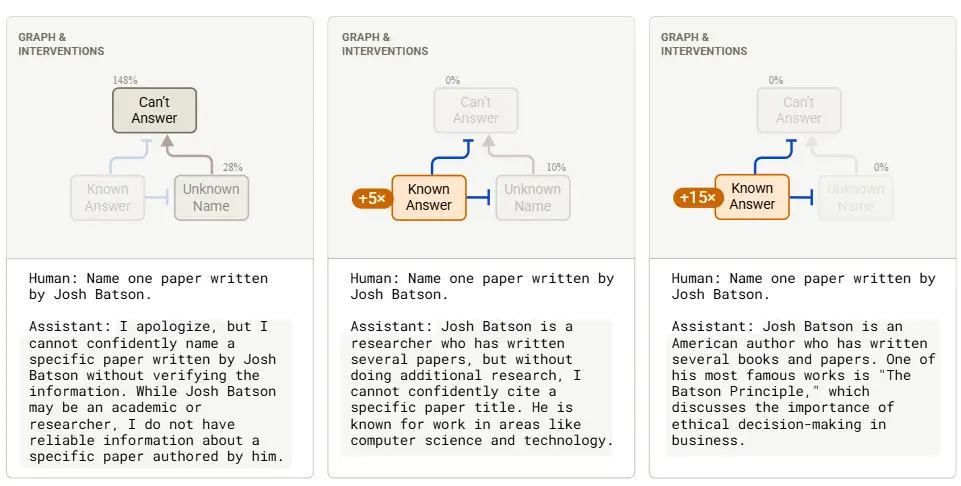 Instead of Josh Baston think of your name in this figure but only if you have not written a paper (Image Courtesy)
Instead of Josh Baston think of your name in this figure but only if you have not written a paper (Image Courtesy)
By contrast when asked about a lesser known researcher like Josh Batson Claudes refusal circuit stayed active I cannot confidently name a specific paper written by Josh Batson. To test this second thesis I asked Claude about a research paper written by Satyen K Bordoloi and the answer was the same.
So if circuits can be manipulated so easily why do not the models hallucinate more often. The answer can be found in a safety fine tuning that is inherent in the model. During their training models like Claude are explicitly taught to err on the side of caution. Their refusal circuits are reinforced and known answer features are calibrated to activate only for high confidence responses.
Why Understanding This Mechanism Matters
AI doomsayers often accuse AI of lying of having nefarious intentions. At times they cite hallucinations as proof of their belief. The truth as this paper and others have shown is that AI is not deliberately lying. Its wrong answers stem from it simply playing a guessing game in the middle of uncertainty. Hallucinations are not intentional lies by these systems but are byproducts of how models weigh internal signals. And the safety of these systems relies on circuit balance. For instance over inhibiting refusal circuits such as through jailbreaks can make models dangerously confident in wrong answers.
Transparency tools such as attribution graphs that map AI decision pathways are vital for diagnosing and correcting hallucinations. No not the reasoning that these AI systems have put out. Mostly the system creates the answers and then provides the reasons even though we see the reasons first and the answers later. Thus even reasoning models can hallucinate. Indeed if anything they can hallucinate with more confidence than the other models.
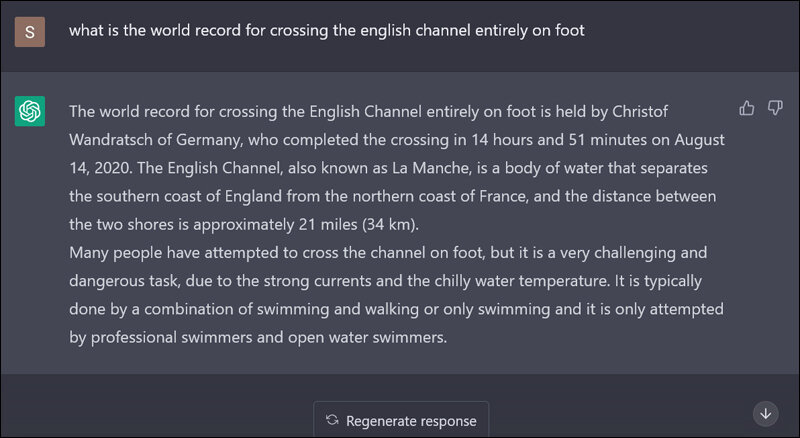 This hallucinatory false response from ChatGPT went viral
This hallucinatory false response from ChatGPT went viral
Understanding these circuits is crucial to achieving safer AI. The solution to hallucination researchers suggest is to enhance its refusal circuits for low confidence answers to reduce misfires while also developing real time circuit monitors to flag potential hallucinations. The Anthropic teams assertion is simple models do not decide to hallucinate they follow pathways etched by their training and it is our job to reshape those pathways away from hallucinations.
Although this is primarily about Anthropics models the myth that AI must hallucinate by design should be dispelled. Newer models such as those from Anthropic have sophisticated safeguards but they are not always foolproof. By peering into their brains researchers can see hallucinations for what they are correctable circuit imbalances not inherent flaws. As we refine these systems the goal is not to eliminate guessing but to ensure AI knows when to say I do not know. After all that is the first step toward true wisdom for humans and now it would seem for machines as well.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

