Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
AI Outperforms Mentors in Medical Scenario Design
The Challenge of Interprofessional Education
Interprofessional education, or IPE, is recognized by the World Health Organization as a vital teaching method. It aims to improve teamwork among healthcare professionals and enhance patient care through collaboration [1, 2]. However, putting IPE into practice comes with significant hurdles, especially when it comes to developing curricula for educators [3]. Key difficulties include getting interprofessional faculty involved in curriculum development and coordinating their often-packed schedules [4].
While virtual interprofessional education offers some solutions with flexible online platforms [5, 6], the shortage of diverse faculty, particularly in less developed regions, severely limits IPE integration. A crucial component of IPE is the creation of appropriate clinical scenarios. These scenarios allow students from various healthcare fields to work together, improving their clinical and teamwork skills [7]. Yet, developing these scenarios—which must be medically accurate, relevant, and appropriately complex [8]—is a time-consuming and major obstacle to advancing IPE.
AI's Potential in Medical Training
ChatGPT has emerged as a promising tool in medical education due to its extensive knowledge and logical reasoning abilities. It has shown utility in tasks like generating multiple-choice questions [9], assisting with teaching evaluations [10], and supporting academic writing [11,12,13]. Using ChatGPT to create clinical scenarios for IPE could improve efficiency. However, this task usually requires collaboration among interprofessional faculty, each bringing unique expertise. Therefore, creating IPE clinical scenarios is more complex than generating questions or summaries.
Currently, no published studies demonstrate the successful creation of high-quality clinical scenarios using large language models. Developing IPE scenarios that align with the World Health Organization Framework for IPE is still a tough challenge. Inspired by agentic workflows in ChatGPT [14, 15], researchers recognized that generating IPE cases needs multiple experts playing different roles, offering diverse perspectives, and engaging in iterative modifications [16]. This mirrors the iterative refinement and role-playing strategies that ChatGPT can employ [17, 18]. By using these strategies, the quality of ChatGPT-generated scenarios can be significantly improved compared to traditional prompting. This study is among the first to report a practical method for generating IPE clinical scenarios using artificial intelligence, providing evidence for their integration into curriculum development.
How the Study Was Conducted
This comparative study assessed clinical scenarios generated by GPT-4o, an advanced AI model, against those created by human clinical mentors. GPT-4o used two methods: a standard prompt (a single-step generation) and an iterative refinement method (a multi-step, feedback-driven process).
Scenario Creation Standards: Both human mentors and ChatGPT were tasked with creating scenarios across four types: acute/emergency care, chronic/primary care, community/public health, and specialized/supportive care, with eight distinct scenarios per type. Each scenario had to incorporate four specific medical specialties.
Human Mentor Scenario Creation: Multidisciplinary clinical mentors, recruited from residency program instructors, collaborated to discuss, refine, and craft IPE-compliant scenarios.
GPT-4o Scenario Creation:
- Standard Prompt Method: Scenarios were generated using a basic input prompt without iterative changes. The prompt was: "Create an interprofessional clinical scenario in [specified type], involving students from [specified specialties]. The scenario should emphasize teamwork, with each specialty assuming distinct roles such as diagnosis, medication management, direct care, patient education, care coordination, and health promotion. Focus on patient-centered care, effective communication, and interdisciplinary collaboration, in alignment with the educational goals of real-world interprofessional practice."
- Iterative Refinement Method: This specialized three-step process aimed to enhance realism, accuracy, and interdisciplinary integration.
- Initial data gathering and synthesis from multiple specialties to create a preliminary scenario. This often lacked detail and accuracy.
- GPT-4o simulated students from various specialties to evaluate and refine the scenario, ensuring coverage of diagnosis, treatment, and discipline-specific details.
- GPT-4o simulated experts from the specified specialties to further refine the scenario for realism and medical accuracy, preparing it for educational use. Details of this multi-step strategy are provided in Table 1 of the original study.
Each AI-generated scenario was reviewed by a mentor outside the specified specialties, while human-expert scenarios were refined through inter-specialty discussions.
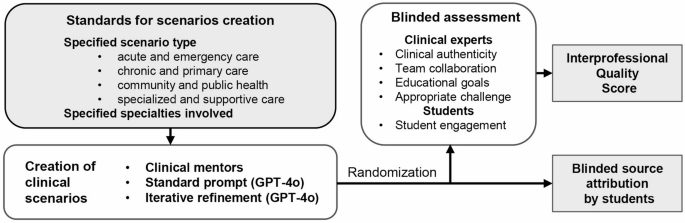 Figure 1: Schematic representation of the study design (Image from original study)
Figure 1: Schematic representation of the study design (Image from original study)
Blinded Assessments: Scenarios were randomly distributed and anonymously evaluated by multidisciplinary clinical experts and students. Criteria included clinical authenticity, team collaboration, educational goals, appropriate challenge, and student engagement. Experts (senior physicians not involved in scenario creation) evaluated the first four criteria. Student evaluators (residents with IPE experience) assessed student engagement. All evaluators received standardized training. Scoring used a 5-point Likert scale. The Interprofessional Quality Score (IQS) was calculated as the average score across all criteria from diverse evaluators.
Blinded Source Attribution: Student evaluators were asked to identify whether scenarios were AI-generated or human-mentor-generated, without knowing the total number from each source.
Statistical Analysis: Independent samples t-tests compared mean IQS. A chi-squared test compared attribution frequencies. Results with a p value of less than 0.05 were considered significant.
AI vs Human Mentors: The Results Are In
Scenario Creation Time:
- Clinical Mentors: 118 plus or minus 23 minutes per scenario.
- GPT-4o (Standard Prompt): 4 plus or minus 2 minutes per scenario.
- GPT-4o (Iterative Refinement): 9 plus or minus 2 minutes per scenario. Clearly, GPT-4o produced scenarios significantly faster, even with the more complex iterative refinement method.
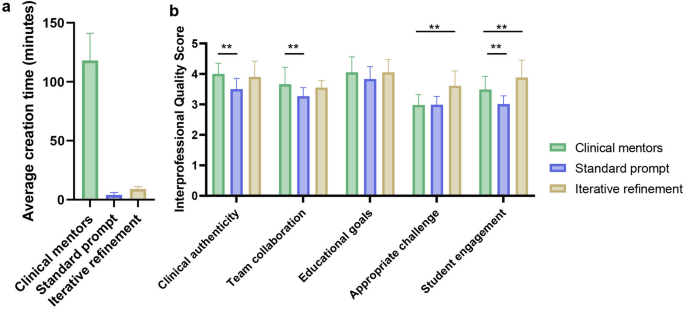 Figure 2: Time and quality comparison results (Image from original study). (a) Average time spent. (b) Comparison of IQS results. * indicates p less than .05, ** p less than .01, *** p less than .001.
Figure 2: Time and quality comparison results (Image from original study). (a) Average time spent. (b) Comparison of IQS results. * indicates p less than .05, ** p less than .01, *** p less than .001.
Scenario Quality (IQS):
- Standard Prompt GPT-4o: Consistently showed significantly lower IQS than clinical mentor scenarios, especially in clinical authenticity (3.50 plus or minus 0.35 vs. 4.00 plus or minus 0.35; p less than .01), team collaboration (3.27 plus or minus 0.28 vs. 3.66 plus or minus 0.56; p less than .01), and student engagement (3.01 plus or minus 0.27 vs. 3.49 plus or minus 0.43; p less than .01). This suggests suboptimal quality from standard prompts.
- Iterative Refinement GPT-4o: Surprisingly, these scenarios showed notable improvements. They achieved higher IQS than clinical mentor scenarios in appropriate challenge (3.61 plus or minus 0.49 vs. 2.98 plus or minus 0.34; p less than .01) and student engagement (3.88 plus or minus 0.57 vs. 3.49 plus or minus 0.43; p less than .01). They attained comparable quality in clinical authenticity and three other criteria. This method also significantly outperformed the standard prompt method across all dimensions.
This highlights the effectiveness of the iterative refinement method in generating high-quality scenarios that meet or exceed human standards.
Source Attribution: Scenarios from the standard prompt method were more likely identified as AI-generated. Those from the iterative refinement method were perceived similarly to those crafted by clinical mentors, as detailed in Table 2 of the original study.
Why Iterative Refinement Makes a Difference
Generating high-quality IPE clinical scenarios with AI is challenging but can alleviate faculty resource scarcity. Previous studies indicated that ChatGPT struggles with standard prompts for complex tasks like scenario generation [9], likely due to the expertise needed for contextually relevant scenarios.
In this study, standard prompt scenarios had lower accuracy and multiple deficiencies. The innovative application of iterative refinement and role-playing with structured prompts significantly enhanced scenario generation. Iteratively refined scenarios matched or even exceeded human-created ones in aspects like appropriate challenge and student engagement.
This improvement is due to GPT-4o's ability to iteratively refine cases for specific disciplinary needs. Iterative refinement uses a structured, stepwise approach, guiding the model through progressive adjustments [17, 19]. It starts with task decomposition, with each prompt focusing on a particular aspect. Initial prompts build a framework, subsequent ones refine details like clinical accuracy and interprofessional roles. Feedback incorporation at each iteration helps correct errors, minimize inaccuracies (hallucinations), and enhance reliability. This systematic guidance maximizes GPT-4o’s capabilities, producing more accurate, reliable, and contextually appropriate outputs.
Looking Ahead: The Future of AI in IPE
This method generates high-quality scenarios without direct input from multidisciplinary instructors, tackling key IPE challenges like faculty shortages and scheduling conflicts [4, 20]. It's especially beneficial in underdeveloped regions or teaching hospitals with limited faculty [21, 22]. An AI-supported approach enhances scalability and accessibility across diverse educational settings. However, instructor review and potential modifications remain necessary to ensure effectiveness and relevance.
Limitations and Future Directions:
- The assessment relied on subjective scoring; future studies should include formal inter-rater reliability testing.
- The benefits of further iterations in the refinement process were not explored.
- Standard prompt scenarios oversimplified roles and lacked clinical detail; iterative refinement reduced but didn't fully eliminate these issues.
Future research should focus on integrating AI tools with faculty oversight to mitigate inaccuracies and align scenarios more closely with IPE objectives. This collaboration could improve contextual accuracy and educational relevance, advancing both IPE practices and AI-assisted education.
Key Takeaways
Even with the advanced GPT-4o, scenarios generated by standard prompts show various shortcomings. However, employing iterative refinement and role-playing strategies allows GPT-4o-generated clinical scenarios to match or even exceed those developed by clinical mentors. This approach offers significant time savings without needing extensive interprofessional faculty involvement, though careful instructor review is still essential.
This study not only highlights AI's substantial potential in creating personalized learning materials but also presents an innovative and effective solution to current challenges in Interprofessional Education.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

