Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
ChatGPT 4 Shows Superior OBGYN Medical Knowledge
The Rise of AI in Medicine
Artificial intelligence (AI), particularly large language models (LLMs) like OpenAI's Generative Pretrained Transformer (GPT), is rapidly changing the technological landscape. With each new version, from GPT-1 in 2018 to the current ChatGPT-4, these models have become exponentially more powerful, demonstrating a remarkable ability to generate human-like text. Their application has spread across numerous fields, including healthcare, where they show promise in assisting with education, research, and clinical decision-making.
ChatGPT-4, launched in March 2023, represents a significant leap from its predecessor, ChatGPT-3.5. OpenAI highlights this by noting that GPT-4 can pass a simulated bar exam in the top 10% of test-takers, while GPT-3.5 scored in the bottom 10%. This improvement is due to a larger context window—allowing it to process more information—and more rigorous safety tuning, making it more reliable for professional use.
While many studies have tested ChatGPT's medical knowledge in various specialties, the field of obstetrics and gynecology has remained relatively underexplored. This study aimed to fill that gap by rigorously evaluating and comparing the knowledge of both ChatGPT-3.5 and ChatGPT-4 in this specific domain, assessing their potential to support clinicians.
Putting AI to the Test: The Study's Method
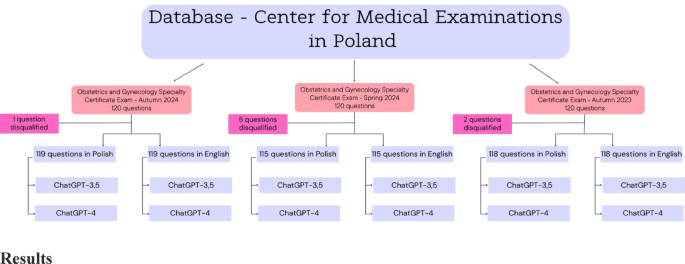
To gauge the AI models' expertise, researchers conducted a comparative cross-sectional study using 352 single-best-answer questions from recent Polish Specialty Certificate Examinations (SCE) in Obstetrics and Gynecology. These exams, which are required for board certification in Poland, contain comprehensive questions based on official guidelines and textbooks.
Each of the 352 questions was submitted to both ChatGPT-3.5 and ChatGPT-4 in two languages: the original Polish and a professionally translated English version. This dual-language approach was designed to determine if the models' primary training language (English) impacted their performance.
The researchers analyzed the accuracy of the models' answers and also considered the official Difficulty Index (DI) of each question, where a value of 1 is very easy and 0 is very difficult. This allowed them to assess if the models' performance changed based on the complexity of the problem.
The Verdict: How Did ChatGPT Perform?
The results revealed a clear and statistically significant superiority of ChatGPT-4 over ChatGPT-3.5 across all tests, regardless of language.
-
Performance in English: This is where the models performed best. ChatGPT-4 achieved accuracy scores ranging from 83.2% to a high of 89.6%. ChatGPT-3.5 also performed respectably, with scores between 63.0% and 73.9%.
-
Performance in Polish: While still knowledgeable, both models saw a drop in accuracy. ChatGPT-4's scores ranged from 76.5% to 83.5%, while ChatGPT-3.5's scores were lower, between 44.5% and 66.0%. In one session, the older model's score fell below the passing threshold of 60%.
-
The Impact of Question Difficulty: The study found a strong correlation between performance and question difficulty. Both models were more likely to answer correctly on easier questions (those with a higher DI). However, they also demonstrated the ability to correctly answer some of the most difficult questions, with ChatGPT-4 successfully tackling a question with a DI as low as 0.133.
What Do These Results Mean for Healthcare?
This study's findings have several important clinical implications. ChatGPT-4's high accuracy, especially in English, suggests it could be a valuable supportive tool for medical education and structured clinical decision-making in obstetrics and gynecology. Its ability to pass every exam it was given underscores its advanced knowledge base.
The performance gap between the two versions, launched only months apart, highlights the staggering pace of AI development. It also emphasizes the importance of using the latest, most advanced models for any critical applications.
The most practical takeaway for users is the clear advantage of using English. Since LLMs are predominantly trained on English data, prompting them in English yields more reliable and accurate results. This is a crucial consideration for healthcare professionals worldwide.
However, the study also sounds a note of caution. The models' struggles with more complex questions and reduced accuracy in non-English languages show the current boundaries of AI. It should be considered a supplementary resource, not a primary source of guidance or a replacement for the nuanced judgment of an experienced clinician, especially in high-stakes scenarios.
Key Takeaways and Future Outlook
In conclusion, ChatGPT-4 demonstrates a high level of obstetric and gynecological knowledge, significantly outperforming its predecessor. Its potential as a clinical aid is promising, but its use should be approached with a clear understanding of its strengths and limitations.
The key takeaways are:
- Use the Latest Version: ChatGPT-4 is substantially more accurate and reliable than ChatGPT-3.5.
- Use English for Prompts: For optimal performance and accuracy, interact with the models in English.
- Recognize Its Limits: AI is better at solving less complex problems and should be used as a supplementary tool, not an autonomous decision-maker.
This study's strengths include its use of validated, high-stakes exam questions and its bilingual analysis. While limited to two models from one developer, the findings provide a crucial, domain-specific evaluation of where this technology stands today and underscore the need for continuous validation as AI becomes further integrated into healthcare.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

