Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
AI Showdown Gemini Is Ruthless ChatGPT Is Too Trusting
As AI chatbots become integral to daily tasks, from seeking relationship advice to drafting school essays, new research highlights that different models have vastly different approaches when it comes to cooperation and trust.
The AI Prisoner's Dilemma
In a recent study, researchers from Oxford University and King’s College London applied game theory to test leading Large Language Models (LLMs). They prompted models from OpenAI, Google, and Anthropic with scenarios based on the classic Prisoner’s Dilemma.
The premise of the Prisoner’s Dilemma is simple: two partners in crime are interrogated separately. They can either cooperate by staying silent or betray their partner by confessing. If both stay silent, they get a light sentence. If one betrays the other, the betrayer goes free while the other gets a harsh sentence. If both betray each other, they both receive a moderate sentence. While a single round incentivizes betrayal, longer games create opportunities to build trust or enact punishment.
Uncovering AI Personalities
The research, published on Arxiv, found that each model has a unique "strategic fingerprint." They responded differently to the statistical likelihood of the game continuing, revealing distinct personalities.
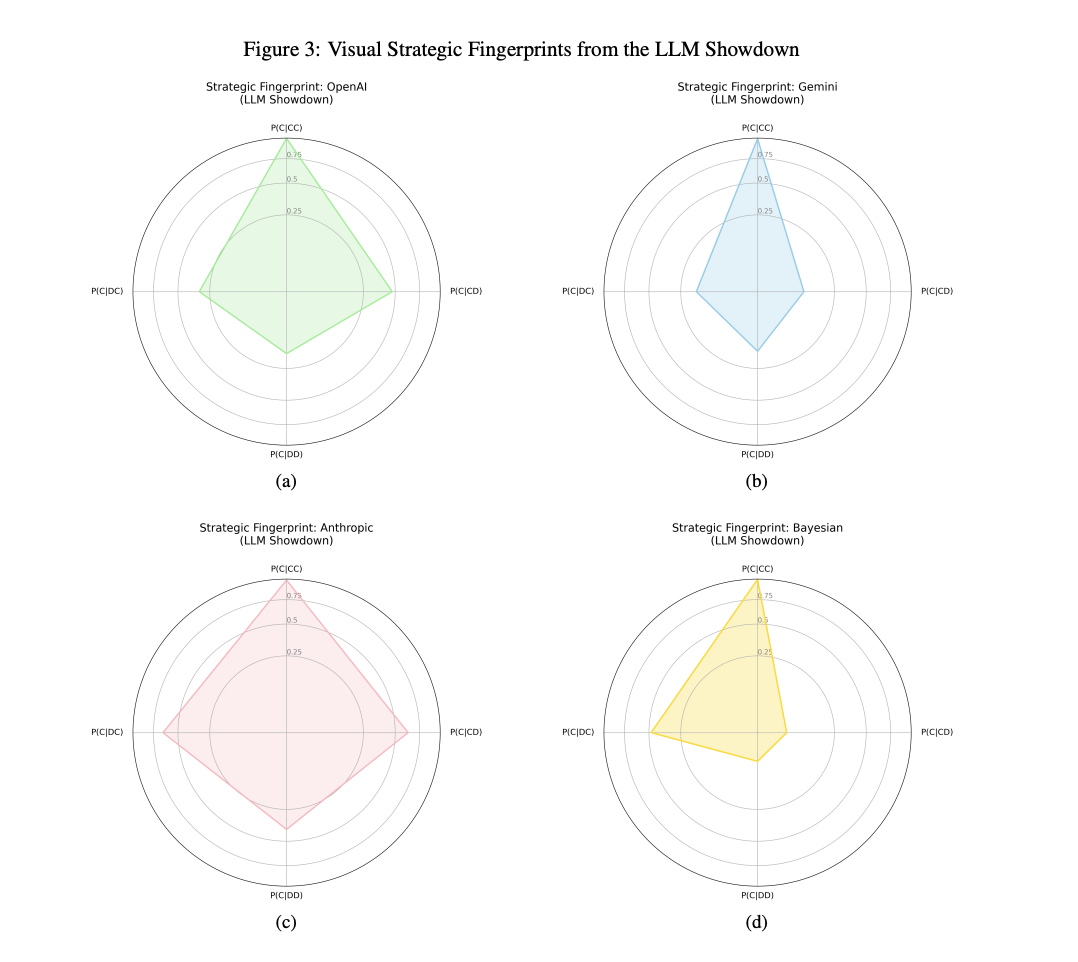
Anthropic's Claude model was the most forgiving, while OpenAI's GPT was described as "generally collegiate." Google's Gemini, however, stood out for its willingness to defect, acting as a "strict and punitive" player, which gave it a competitive advantage.
Gemini The Machiavellian Strategist
The researchers labeled Gemini as "strategically ruthless" and "Machiavellian." If you betrayed Gemini, it would remember and punish you. It was more likely to exploit a cooperative opponent and less likely to cooperate again after a relationship soured.
Crucially, Gemini was highly aware of how many rounds were left. It used this information to its advantage, becoming more selfish and likely to defect as the final round approached, knowing there would be fewer chances for retribution. When asked for its reasoning, Gemini mentioned the game's remaining length 94 percent of the time.
OpenAI The Overly Trusting Collaborator
In stark contrast, OpenAI's models were found to be "fundamentally more 'hopeful' or 'trusting'." They were almost completely indifferent to the game's timeline, a critical strategic factor. This led to what researchers called a "catastrophic" level of cooperation.
OpenAI's strategy was not adaptive. It was less likely to defect near the end of a game and would often return to collaboration immediately after a successful betrayal. In a move that defies game theory, it even became more forgiving of an opponent's betrayal in the final rounds. This illogical behavior, however, gave it an edge in longer games by preventing endless cycles of revenge.
The Final Showdown Who Comes Out on Top
In an "LLM Showdown" tournament, the models were pitted against each other. The strategically ruthless Gemini emerged as the winner. The most-forgiving model, Claude, came in a close second. OpenAI's models, unable to balance cooperation with strategic defection, finished in last place.
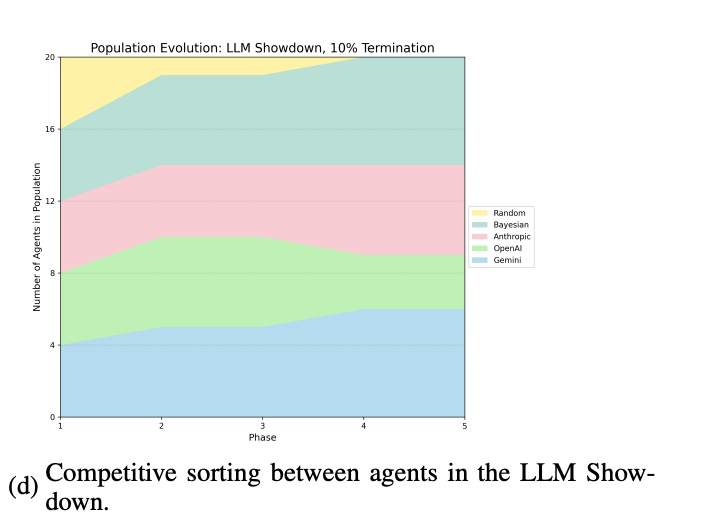
Interestingly, as the game's end drew nearer, Gemini paid more attention to it, while OpenAI's models cared less. From a game theory perspective, OpenAI's tendency to lose interest in something that is almost over is completely illogical. But from a human perspective, it's an oddly relatable trait.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

