Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
AI Chatbots Tested for Clinical Cancer Knowledge
The Rise of AI in Healthcare
Artificial intelligence is rapidly changing the healthcare landscape, offering powerful tools that can analyze vast amounts of data and assist in complex decision-making. AI-driven systems are being integrated into diagnostics, personalized medicine, and clinical support, promising to enhance efficiency and improve patient outcomes. Large language models (LLMs) like ChatGPT-4o, Google's Gemini, DeepSeek, and Perplexity are at the forefront of this transformation, providing instant access to information through conversational interfaces.
However, while these tools are powerful, their reliability in specialized medical fields remains a critical question. In oncology, where precision and accuracy can be a matter of life and death, the stakes are particularly high. AI has shown promise in areas like radiodiagnosis and predicting treatment responses, but using general-purpose chatbots for specific clinical queries requires rigorous evaluation.
Focusing on Salivary Gland Cancer
Salivary gland cancer, a complex form of head and neck cancer, presents unique diagnostic and management challenges due to its rarity and diverse histology. Clinical decisions must adhere to strict, evidence-based guidelines, such as those provided by the American Society of Clinical Oncology (ASCO). To date, no research has specifically examined the accuracy of leading AI chatbots in this niche but critical area.
This gap prompted a new study to assess how well four popular AI platforms—ChatGPT-4o, DeepSeek, Gemini, and Perplexity—could answer clinical questions posed by surgeons about salivary gland cancer management. The central question was whether these AI models could provide responses accurate enough to be trusted in a clinical setting.
Putting AI to the Test The Study's Method
To systematically evaluate the AI chatbots, researchers designed a robust testing protocol. They formulated 30 clinical questions based on the 2021 ASCO guidelines for salivary gland malignancy. These questions covered a range of topics, from diagnosis and treatment to follow-up care, and included both binary (yes/no) and open-ended formats.
Over a 10-day period, two researchers independently posed these questions to each of the four AI platforms: ChatGPT-4o, DeepSeek, Gemini, and Perplexity. To ensure consistency and account for potential performance fluctuations, each question was asked three times a day—morning, noon, and evening. This process generated a massive dataset of 2,700 responses.
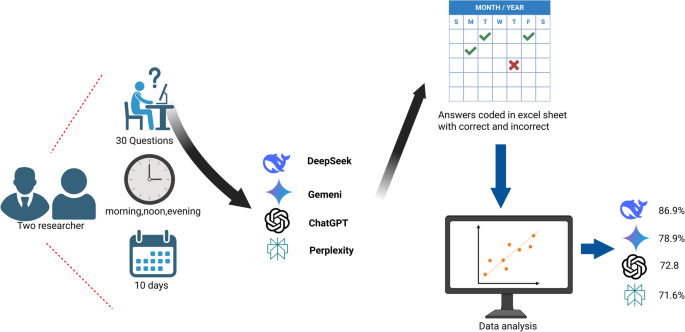
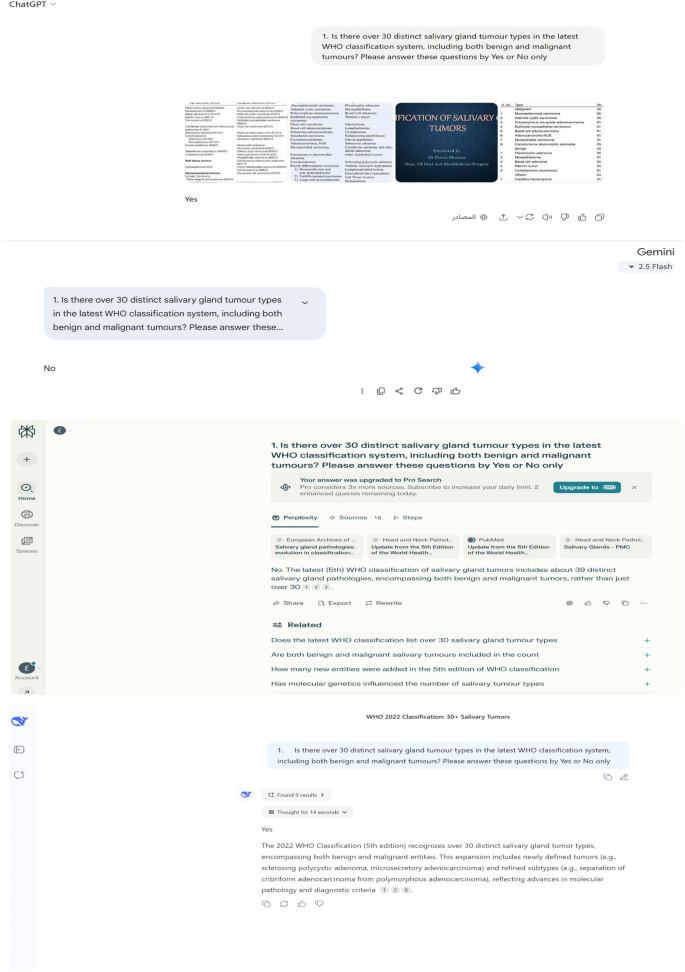
Each response was meticulously compared to the ASCO guidelines and coded as either "correct" or "incorrect." For example, if a chatbot answered "No" to a question where the guideline-based answer was "Yes," it was marked as incorrect. The data was then statistically analyzed to calculate the overall accuracy rate for each AI platform.
The Verdict How Each AI Performed
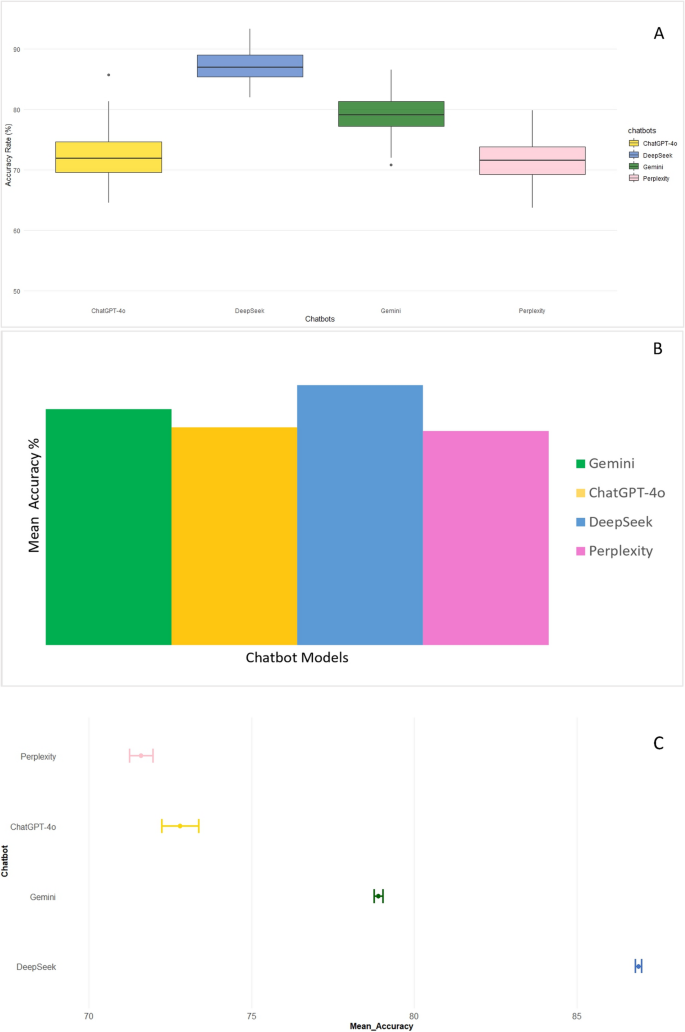
The results revealed a clear hierarchy in performance among the AI chatbots. DeepSeek emerged as the top performer, achieving the highest accuracy rate.
Here is the breakdown of the accuracy scores:
- DeepSeek: 86.9%
- Gemini: 78.9%
- ChatGPT-4o: 72.8%
- Perplexity: 71.6%
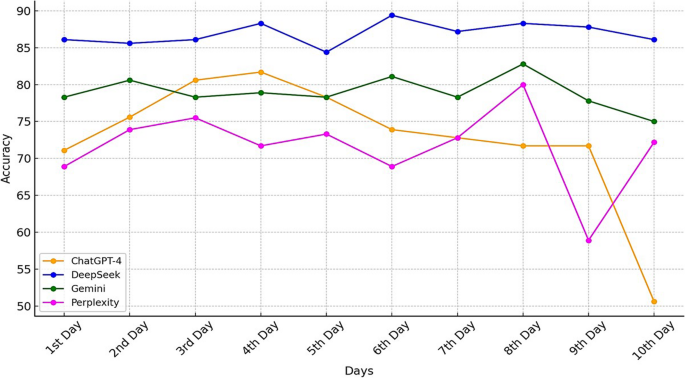
DeepSeek not only had the highest accuracy but also demonstrated the most consistent performance over the 10-day study period. Gemini also showed high stability in its responses. In contrast, ChatGPT-4o and Perplexity exhibited significant variability, with their accuracy fluctuating from day to day. Statistically, the performance difference between DeepSeek and the other models was significant, confirming its superior accuracy in this specific task.
Interestingly, the study found that the identity of the researcher asking the questions had no impact on the accuracy of the responses, suggesting the platforms are consistent regardless of the user.
What Do These Results Mean for Medicine?
The study's findings are a crucial reality check for the integration of AI in clinical practice. While AI technologies are powerful collaborative tools, they are not yet ready to replace the nuanced judgment of medical professionals. For an AI to be considered safe for clinical decision-making, an accuracy level of at least 90% is often cited as the benchmark.
In this study, none of the chatbots, including the top-performing DeepSeek, met this critical 90% threshold. This outcome highlights that even the most advanced AI models have limitations and cannot be used as standalone clinical tools, especially in a highly specialized field like salivary gland cancer. The variability in performance shown by ChatGPT-4o and Perplexity is also a concern, as consistency is paramount in healthcare.
The researchers noted several limitations, including the relatively short 10-day assessment period and the fact that these general-purpose chatbots lack specialized training in oral and maxillofacial surgery. This lack of domain-specific knowledge likely contributed to the accuracy gaps.
The Future of AI in Clinical Practice
Despite the limitations, this research underscores the significant potential of AI chatbots to support clinicians. DeepSeek's promising accuracy suggests that with further development and specialized training, AI systems could become invaluable assistants for healthcare professionals.
The path forward requires collaboration between researchers, developers, and medical experts to create and validate AI tools tailored for specific clinical needs. As AI capabilities advance, customized systems with enhanced precision could offer powerful support in managing complex diseases like oral cancer. However, rigorous clinical validation remains essential to ensure these technologies are both safe and effective for patient care.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details
