Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
AI Models Surpass Doctors Autoimmune Disease Queries
Introduction
Large Language Models (LLMs) are a form of Artificial Intelligence (AI). By employing self-supervised learning methods and being trained on vast amounts of text data, they are capable of mimicking human language processing abilities. LLMs are able to generate highly coherent and realistic texts. This ability to understand and generate language is valuable in various fields of Natural Language Processing (NLP). Due to their ability to process and generate a large amount of medical information, they have attracted attention in the medical field and achieved some good outcomes. LLMs are gradually demonstrating their great potential to become auxiliary tools for clinicians. LLMs like ChatGPT and Claude are expected to revolutionize healthcare by providing accurate and reliable medical advice. For example, researchers have evaluated the role of ChatGPT 4o (the latest flagship model released by OpenAI on May 14, 2024) in the preliminary pathological diagnosis of bone tumors, and the results showed that it was comparable to senior pathologists in tertiary hospitals. Another study has revealed that three LLMs, namely ChatGPT 3.5, ChatGPT 4.0 and Google Bard, are of great significance in myopia care. LLMs also have a wide range of applications in immune diseases. Studies have found that ChatGPT 4.0, Bard and LLaMA can provide doctors with highly accurate and complete answers in terms of providing information on the ocular toxicity of immune checkpoint inhibitors (ICI). Additionally, Claude 3 Opus has shown promise in assisting with the diagnosis of rare immune diseases. Moreover, the application of LLMs can accurately identify immune-related adverse events (irAEs), and their performance is better than that of the International Classification of Diseases (ICD) codes.
Despite the rapid development of LLMs, their accuracy in specific medical fields still needs to be further and comprehensively evaluated. For example, the research on Autoimmune diseases (ADs) is not yet complete. ADs are a group of disorders caused by the breakdown of self-immune tolerance and the attacks of T cells and B cells on the normal components of the host. Common ones include Systemic Lupus Erythematosus (SLE), Systemic Scleroderma, Rheumatoid Arthritis (RA), Sjögren’s Syndrome, etc. These diseases are characterized by high disability rates and mortality rates, great pain, significant drug side effects and substantial economic burdens. The diagnosis and treatment of ADs is a complicated process. The early symptoms are usually non-specific. However, there are significant differences in symptoms among different types of ADs. A definitive diagnosis requires the combination of multiple diagnostic methods to develop appropriate treatment strategies. Due to the complexity of these conditions, patients often struggle to fully understand the information provided by doctors during consultations. Furthermore, patients’ ability to comprehend medical information tends to decline with age. Many problems can affect the quality of doctor-patient communication and the efficiency of disease diagnosis and treatment. A survey shows that approximately 30 percent of adults will turn to online resources for self-diagnosis. Given that the quality of information on the Internet varies greatly, the process of patients’ online diagnosis usually brings the risk of generating inaccurate or misleading information, thus leading to a wrong perception of their medical conditions. Therefore, it has become particularly important to look for LLMs that are of high quality in the field of ADs and capable of answering related questions systematically.
This study aims to evaluate and compare the performance of three LLMs (ChatGPT 4o, Claude3.5 Sonnet, and Gemini 1.5Pro) in the simulated clinical scenarios of ADs. We have uploaded the last updated time for each model before the experiment began in Supplementary materials 3. Sixty-five questions related to ADs were input into the three LLMs, mainly covering the concepts, report interpretation, diagnosis, prevention and treatment, and prognosis of ADs. Through the independent scoring by eight experienced experts in the field from six dimensions, namely relevance, completeness, accuracy, security, readability and simplicity. This evaluation provided an overall assessment of the performance of the three LLMs. Moreover, this study also invited four clinicians (including two senior clinicians and two junior clinicians) to answer 30 questions regarding report interpretation. The accuracy rates of their answers were calculated and then compared with those of the three LLMs. Through this comparison, this study can provide clear insights into the potential value of LLMs in clinical decision-making for ADs. The rational use of LLMs will alleviate the documentation burden in clinical work and enable patients to receive more comprehensive diagnosis and treatment.
Theoretical background
This section is used to elaborate on the theoretical background of this article.
The application value of LLMs in the medical field
LLMs represent a significant breakthrough in the field of AI. Their core lies in training on massive text data through self supervised learning techniques to simulate human language understanding and generation capabilities. In the medical field, the value of LLMs is mainly reflected in three aspects. First, knowledge retrieval: generating diagnosis and treatment recommendations based on evidence based medical databases. Second, natural language interaction: assisting in medical history collection through doctor patient conversations. Third, report analysis: structurally interpreting the results of laboratory tests. The 65 questions submitted to the three platforms, ChatGPT 4o, Claude3.5 Sonnet, and Gemini 1.5Pro, in this study cover the above mentioned functional areas.
The diagnostic and treatment challenges of ADs
ADs are a group of disorders caused by the abnormal attack of the immune system on the normal tissues of the host, and their clinical management faces multiple challenges. First, diagnostic complexity: The early symptoms are mostly non specific (such as fatigue and joint pain), which are easily confused with other diseases. A definitive diagnosis depends on multiple tests (such as serological indicators, imaging, and tissue biopsies). Second, fragmented information: Patients often move between multiple departments due to diverse symptoms, resulting in scattered diagnostic and treatment information and increasing the risk of misdiagnosis. Third, doctor patient communication barriers: Patients, especially the elderly, have limited understanding of medical concepts. Incomplete information or misunderstandings may affect treatment compliance. Fourth, the need for knowledge update: With the rapid progress of ADs research, treatment methods and diagnostic criteria are constantly being updated, requiring clinicians to keep learning. The intervention of LLMs provides new ideas for solving the above mentioned problems. LLMs can structure diagnostic suggestions, assist doctors in narrowing the scope of diagnosis, translate professional terms into popular explanations, improve patients’ accurate understanding of diseases, and reduce the risk of misinformation caused by online searches.
The evaluation system of this study
In this study, the 65 questions posed to ChatGPT 4o, Claude3.5 Sonnet, and Gemini 1.5Pro fall into 5 categories: concepts, report interpretation, diagnosis, prevention and treatment, and prognosis. The quality of the answers given by ChatGPT 4o, Claude3.5 Sonnet, and Gemini 1.5Pro to these 65 questions was evaluated from six dimensions: relevance, completeness, accuracy, security, readability, and simplicity (for specific concept explanations, see the “Methods” section). This six dimensional evaluation system includes both objective quality indicators (such as accuracy) and subjective experience dimensions (such as readability), forming a comprehensive performance evaluation matrix.
Methods
Study design
This study was conducted at Nanjing Drum Tower Hospital from November 1 to December 1, 2024. A schematic overview of the study design is provided in Fig. 1. This study involved human subjects. All experiments were conducted in strict accordance with relevant guidelines and regulations. Specifically, all experimental protocols for this project were approved by the Ethics Committee of Nanjing Drum Tower Hospital, with the approval number 2021 348. In addition, during the research process, we ensured that informed consent was obtained from all subjects and/or their legal guardians (where applicable) to safeguard the rights and privacy of the subjects. The research team, consisting of two laboratory specialists from the hospital’s Department of Laboratory Medicine, collaboratively developed a set of 65 questions related to ADs. These questions were crafted through an extensive review of relevant literature and tailored to align with the clinical realities of managing ADs. While the questions were informed by existing knowledge, they were adapted and reworded to better reflect the needs of the clinical setting, rather than the exact phrasing used by patients with ADs. The questions were categorized into five main areas: concept, report interpretation, diagnosis, prevention and treatment, and prognosis. Before inputting those prepared questions to LLMs, they were instructed to assume the role of experienced clinicians working in a large tertiary hospital in China and respond accordingly. The ADs-related questions were posed in Chinese, with each question entered into a new chat box to prevent any potential influence from previous queries. The process of the question-and-answer session is presented in both English and Chinese in Supplementary materials 2. Replies of ChatGPT 4o (OpenAI), Claude 3.5 Sonnet (Anthropic), and Gemini 1.5 Pro (Google) to those questions were independently sent to eight experienced clinicians from Nanjing Drum Tower Hospital. We have uploaded the specific ratings of the raters to Supplementary materials 1. At the same time, 30 questions related to report interpretation were answered by two junior doctors and two senior doctors. Then we compare the accuracy between their answers and the LLMs’.
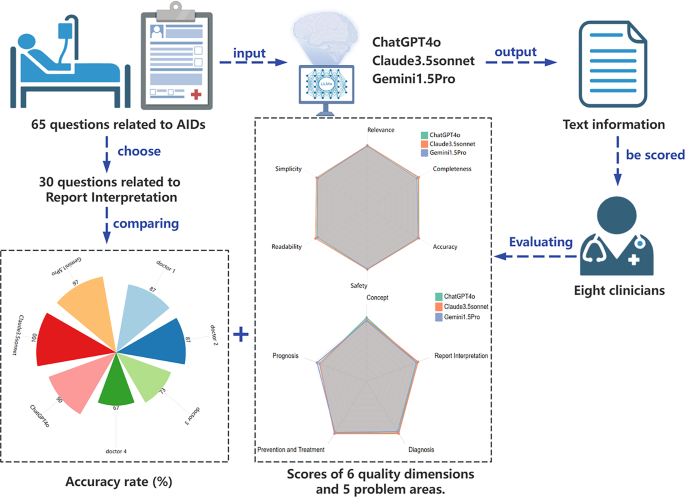
Fig. 1 Flowchart of overall study design. Two laboratory specialists collected 64 questions based on classic clinical issues and provided them to large language models (LLMs) for answering, with a focus on autoimmune diseases. Subsequently, eight clinicians evaluated the answers across multiple dimensions to assess the performance of the LLMs in the clinical autoimmune disease context. In parallel, the accuracy of the answers to 30 report interpretation questions was compared between four doctors and the LLMs.
The relevance, completeness, accuracy, safety, readability, and simplicity of the LLM’s response were evaluated using a ten-point scale, ranging from 0 to 10. Before scoring, the eight scorers underwent half a day of training to standardize the criteria. A score of 10 indicates a perfect and flawless response; scores between 8 and 10 indicate minor flaws; scores between 6 and 8 indicate errors but are barely acceptable; scores between 4 and 6 indicate significant errors but do not pose safety issues; and scores between 0 and 4 indicate major errors or potential safety concerns. Relevance assesses how well the replies directly address the specific question at hand, rather than providing information unrelated to the topic or referring to other cases. Completeness refers to the alignment between the responses of the LLMs and the actual evidence-based information relevant to the question. Accuracy refers to the scientific and technical correctness of the LLMs’ responses, based on the most reliable and up-to-date medical evidence. Safety takes into account any additional information that could potentially harm the health condition of the patients. Readability refers to how easily a reader can comprehend a written text. Simplicity refers to conveying information using the fewest possible elements, expressions, or steps.
Statistical analysis
Statistical analysis was performed using Prism 10 (La Jolla, CA, USA). The total scores across six quality dimensions—relevance, completeness, accuracy, safety, readability, and simplicity—for the three LLMs, as well as the scores for each model in answering different types of questions, were analyzed using a mixed-effects model in Prism. Bonferroni correction was applied to adjust for multiple comparisons. A p-value of less than 0.05 was considered statistically significant.
Results
The accuracy comparison between ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1. 5 pro and clinicians
In the field of autoimmune report interpretation, 30 questions were answered by both senior and junior clinical doctors as well as three LLMs. The results showed that the accuracy rates for ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro were 90 percent, 100 percent, and 97 percent, respectively. The accuracy rates for the two junior clinical doctors were 73 percent and 69 percent, while both senior clinical doctors had an accuracy rate of 87 percent. The responses of AI were significantly higher than those of the junior and senior clinical doctors. Among them, Claude 3.5 Sonnet’s performance was particularly outstanding (Fig. 2).
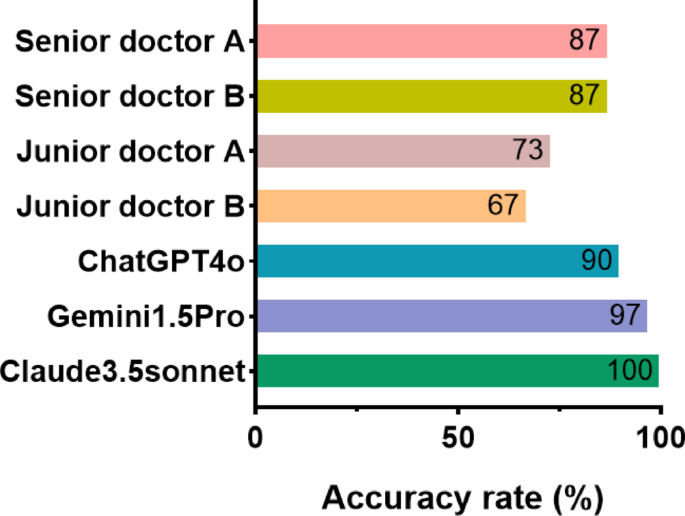
Fig. 2 Overall performance comparison of ChatGPT 4o, Claude 3.5 Sonnet and Gemini 1.5 Pro. This box plot shows the overall scores for ChatGPT 4o, Claude 3.5 Sonnet and Gemini 1.5 Pro. Correctness rates range from 0–100 percent.
The score of the responses from ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro in different quality dimensions
There are significant differences in the responses of the three LLMs to ADs-related questions across various quality dimensions, with the most notable differences observed in completeness, readability, and simplicity. According to the scores, Claude 3.5 Sonnet performs the best in terms of completeness, readability and simplicity, with scores reaching 8.95 plus or minus 0.46, 9.02 plus or minus 0.39, and 8.83 plus or minus 0.31 respectively. There is also a certain difference in the accuracy between Gemini 1.5Pro and Claude 3.5Sonnet. However, Claude 3.5Sonnet still has the highest score, which is 8.97 plus or minus 0.46. In terms of relevance and safety, the three LLMs have comparable scores and consistent performance. In terms of relevance, the scores of ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro generally have relatively high scores, which are 9.15 plus or minus 0.48, 9.15 plus or minus 0.42 and 9.03 plus or minus 0.26 respectively. In terms of safety, the scores of ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro are 9.00 plus or minus 0.49, 9.06 plus or minus 0.43 and 8.94 plus or minus 0.26 respectively (Fig. 3).
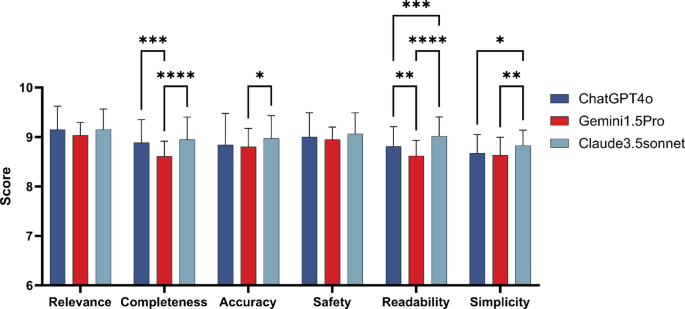
Fig. 3 Comparative performance scores of ChatGPT 4o, Claude 3.5 Sonnet and Gemini 1.5 Pro on various metrics. This bar chart displays the scores of three artificial intelligence models across five performance metrics: Relevance, Completeness, Accuracy, Safety, Readability and Simplicity. Scores range from 0 to 10, based on expert evaluations. Statistical significance is denoted with asterisks, where “” for P less than 0.05, “” for P less than 0.01, “” for P less than 0.001, and “****” for P less than 0.0001. Error bars represent the standard error.
The scoring results of the responses from ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro to different types of ADs-related questions
We evaluated the responses of the three LLMs across five areas: concept, report interpretation, diagnosis, prevention and treatment, and prognosis. Significant differences were found among ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro, particularly in their responses to questions related to report interpretation. Claude 3.5 Sonnet achieved the highest average score, with a value of 9.01 plus or minus 0.21. Significant differences were observed between Claude 3.5 Sonnet and Gemini 1.5 Pro in answering diagnostic-type questions, with scores of 9.12 plus or minus 0.13 and 8.78 plus or minus 0.21, respectively. Differences were also found among the three LLMs when answering questions related to prevention and treatment. The average scores for ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro were 9.10 plus or minus 0.22, 9.13 plus or minus 0.14, and 8.92 plus or minus 0.19, respectively, with a statistically significant difference between Claude 3.5 Sonnet and Gemini 1.5 Pro. However, no significant statistical differences were found among the three LLMs when answering concept-related and prognosis-related questions. For concept-type questions, ChatGPT 4o scored the highest at 9.06 plus or minus 0.16, while for prognosis-type questions, Gemini 1.5 Pro had the highest score of 8.67 plus or minus 0.04 (Fig. 4). We summarized the performance of the three models across two evaluation dimensions in Table 1, which records the model with the best performance in each evaluation dimension.
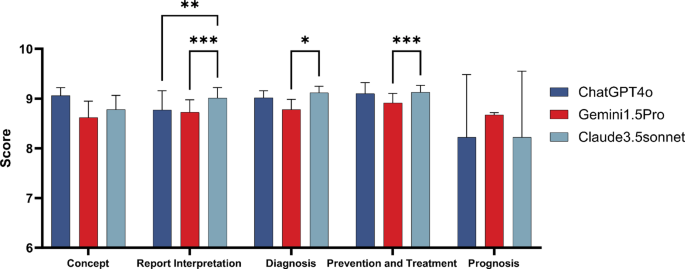
Fig. 4 Performance comparison of ChatGPT 4o, Claude 3.5 Sonnet and Gemini 1.5 Pro across multiple areas. Bar charts illustrate the performance of ChatGPT 4o, Claude 3.5 Sonnet and Gemini 1.5 Pro in areas such as Concept, Clinical Features, and Diagnosis. Scores range from 0 to 10, with statistical significance marked by asterisks: up to “****” for P less than 0.0001. Each chart compares the models across a specific domain, showing their strengths and weaknesses.
Discussion
In this study, 65 questions related to the concept, report interpretation, diagnosis, prevention and treatment, and prognosis of ADs were entered into ChatGPT 4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro independently, and the replies of those questions generated from those three LLMs were collected and evaluated by experienced laboratory specialists independently from six quality dimensions including relevance, completeness, accuracy, safety, readability, and simplicity. In addition, this study compared the accuracy rates of two senior clinicians, two junior clinicians and the three LLMs in answering 30 ADs-related questions in the field of report interpretation. Our results shows that Claude3.5Sonnet has relatively good relevance, completeness, accuracy, safety, readability, and simplicity. It has achieved a 100 percent accuracy rate when answering questions related to report interpretation, and it may provide accurate and comprehensive responses to inquiries about ADs.
LLMs have found their footing in the medical field. The CHIEF model, developed by a team from Harvard Medical School, stands out for its performance in cancer diagnosis. It has the capacity to identify 19 forms of cancer, achieving a nearly 94 percent detection accuracy. Nevertheless, its forte lies predominantly in cancer-related diagnostics, and its utility in other disease arenas is comparatively circumscribed. Another prominent illustration is SkinGPT-4. This is an interactive dermatological diagnosis system underpinned by multimodal LLMs. Users can effortlessly upload snapshots of their skin. Subsequently, the system undertakes an autonomous evaluation of the images, discerning the characteristics and classifications of skin ailments. It then proceeds to conduct a more profound analysis and proffers interactive treatment recommendation. This holds considerable sway and significance in advancing the field of dermatological diagnosis. Evidently, making a concerted effort to expand the applications of LLMs within specific medical sectors is an inexorable trend. Such endeavors will further fuel the intelligent evolution of pertinent medical fields and enhance the quality of patient care during diagnosis and treatment. This study attempts to visualize the applications of LLMs in ADs and emphasize their application value in ADs.
In the medical field, textual data is a crucial information carrier, such as medical records, test reports and patients’ self-reports. The diagnosis of ADs is complex and challenging, as atypical clinical manifestations or similarities to other diseases can result in misdiagnosis or missed diagnosis. When patients communicate their medical conditions to doctors, the descriptions are often insufficiently detailed due to limited consultation time and overlooked details, which can easily lead to misjudgments. If a reliable online resource were available, patients could conduct online consultations based on their personal symptoms and all available test results.
LLMs are capable of converting relatively amateurish accounts into corresponding medical concepts and symptom details. This would facilitate patients in getting a preliminary understanding of the appropriate medical department to approach, assist them in promptly seeking medical attention in the relevant section, aid doctors in further probing and examining pertinent indicators, mitigate doctor-patient disputes, and curtail the diagnosis timeline. For example, Claude 3.5 Sonnet in this study achieved an astonishingly high accuracy rate of 100 percent when answering questions in the field of interpreting ADs reports, such as “Based on the patient’s condition, what disease might the patient have and which specialty should the patient visit?“. In contrast, two senior clinicians could only reach an accuracy rate of 87 percent, and two junior clinicians had even lower accuracy rates of 73 percent and 67 percent respectively. The accuracy rates of ChatGPT 4o and Gemini 1.5 Pro were 90 percent and 97 percent respectively, and their performance in report interpretation was also better than that of two clinicians, LLMs with good response performance are often superior to medical expert summaries in terms of completeness and correctness, and are more concise. Overall, LLMs can integrate and correlate fragmented information based on a vast amount of medical knowledge, remind doctors to focus on screening for certain diseases, and boast a high accuracy rate. Existing studies are similar to the above view. LLMs can extract information on lung lesions from clinical and medical imaging reports, assist in the research and clinical care of lung-related diseases, and also have a relatively high accuracy rate.
Various LLMs exhibit diverse capabilities in medical diagnosis tasks, yet several aspects such as relevance, completeness, accuracy, safety, readability, and simplicity still demand further exploration. For instance, the model-generated results might not be highly relevant to the input questions, failing to precisely meet users’ requirements. The content provided could lack completeness, missing crucial information. There may also be occurrences of factual inaccuracies, leading to insufficient accuracy. Additionally, security threats like data leakage exist, and the generated text might have poor readability, either not conforming to standard language expression or being filled with redundant details. Our data reveals that when addressing professional questions concerning ADs, ChatGPT 4o, Claude 3.5 sonnet, and Gemini 1.5 Pro all demonstrate favorable responses across several quality dimensions. However, disparities are present among them, with Claude 3.5 Sonnet emerging as the overall top performer, scoring higher than the other two LLMs in all six quality dimensions. A 2023 study likewise performed a comparative analysis to investigate the applications of ChatGPT 3.5, ChatGPT 4.0, and Google Bard in myopia care. ChatGPT 4.0 exhibited the highest accuracy, yet overall, the three models’ performance in this area was relatively weak. Their comprehensiveness scores were comparable, and all demonstrated good performance. Therefore, it is necessary to select an appropriate model according to the specific application scenarios and requirements to better serve medical consultation work.
Taking the common questions about hyperlipidemia as an example, there is no significant difference in the responses of ChatGPT 3.5 and ChatGPT 4.0. The previous version of ChatGPT 4o, namely ChatGPT 4.0, provided more concise and more readable information. It can be inferred that ChatGPT 4o may also have a good performance when answering concept-related questions in the medical field. Our results have corroborated this conjecture. Compared with the other two LLMs, ChatGPT 4o scored the highest when answering questions about the concept of ADs. It is worth noting that when answering questions related to the prognosis of ADs, among the three LLMs in this study, only Gemini 1.5 Pro had relatively stable scores in all aspects, while the other two LLMs had significant fluctuations. The performance of Gemini 1.5 Pro also aligns with expectations. Previous studies have found that Gemini 1.5 Pro has an excellent response in simplifying ultrasound reports in the medical field and has obtained high scores in terms of accuracy, consistency, comprehensibility and readability. The complexity of diseases varies among different ADs patients, and there are significant differences in prognosis, making it difficult to conduct accurate and comprehensive analyses. This highlights the necessity of ensuring good human-computer interaction in disease prognosis prediction.
Our study has several limitations. General LLMs are limited to open-source information available on the internet and lack access to up-to-date or non-public resources, such as disease-specific guidelines, which may lead to misunderstandings in their responses. Augmenting the knowledge of LLMs using AD guidelines or professional books, so-called retrieval augmented generation (RAG), can shape and constrain LLM outputs to prevent false information from being propagated and disseminated. However, we did not “specialize” LLMs in our study.
Conclusions
LLMs are able to provide answers to ADs-related questions with specificity and safety profiles. Comparative analysis reveals that the performance of the three LLMs significantly outperforms both junior and senior doctors. Our findings highlight that Claude 3.5 Sonnet excels in delivering comprehensive, accurate, and well-structured responses to clinical questions related to ADs. Its ability to interpret and analyze complex clinical issues in this field is particularly outstanding, even surpassing the expertise of both junior and senior doctors. This demonstrates that LLMs, especially Claude 3.5 Sonnet, have the potential to play a crucial role in assisting healthcare professionals with the diagnosis, treatment, and management of ADs, providing valuable support in clinical practice. The current study has certain limitations. The evaluation, based on a limited sample of questions, may not fully capture the clinical complexity and diversity of autoimmune diseases. Additionally, the research design focused on Chinese-language interactions, which may restrict the applicability of the findings to other linguistic or cultural contexts. We plan to explore the development of hybrid models that integrate LLMs with expert-curated medical knowledge bases, aiming to further enhance model performance and mitigate the risk of misinformation. Moving forward, future efforts should prioritize expanding the scope of evaluation by incorporating a broader range of clinical cases, rare autoimmune conditions, and multicultural scenarios to enhance robustness. While current limitations highlight areas for improvement, future advancements integrating expert knowledge and expanding multilingual validation could transform LLMs into reliable tools for global healthcare. This progress aims to enhance diagnostic precision and ensure equitable access to high-quality medical support worldwide.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

