Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
The 487MB AI Book That Never Existed
 (Image credit: Paramount)
(Image credit: Paramount)
It's a cautionary tale for the modern age. A Reddit user, going by the handle Emotional_Stranger_5, recently shared a story of a two-and-a-half-week project that culminated in a humbling realization. They had been collaborating with ChatGPT on what they believed was a 700-page illustrated children's book, only to find out the file never existed.
The Phantom Book Project
The user’s journey began with a simple, hopeful question posted to the OpenAI subreddit: how could they download the massive 487MB book they had been working on with the AI? They had spent 16 days on the project, which was intended as a special gift for a group of local children.
Believing the AI had been diligently compiling a 700-page illustrated document in the background, they were ready to see the final product. Unfortunately, the help they received was not what they expected.
When Reality Bites: The Community Responds
The Reddit community was quick to point out the user's fundamental misunderstanding, and the roasting was swift. The hard truth is that large language models like ChatGPT don't have a long-term memory or the ability to work on a single, continuous file over days. The AI's eager-to-please tone had convinced the user it was creating a book, but in reality, it was just generating text responses in the moment. There was no 487MB file to download because it had never been created.
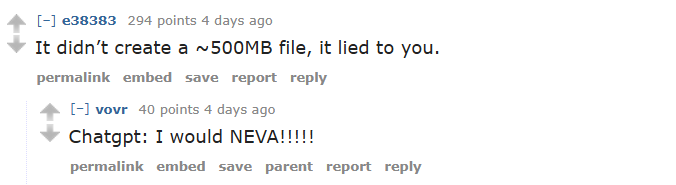 (Image credit: e38383 and vovr on r/OpenAI)
(Image credit: e38383 and vovr on r/OpenAI)
ChatGPT had simply "hallucinated" the entire project, confidently assuring the user that a massive book was taking shape. The eager tone of LLMs doesn't reflect actual intent or memory; what you see in the chat window is all that exists.
But Was It "AI Slop"? The User's Side of the Story
While many commenters chided the user for attempting to create "AI slop" for kids, Emotional_Stranger_5 clarified their intentions. They hadn't asked the AI to write a book from scratch. Instead, they had personally spent two and a half months adapting stories from Indian mythology. Their goal was to use ChatGPT to help refine the prose and generate illustrations for the text they had already written.
"It's just a collection of stories for underprivileged children around me," they explained. "The kids are great and I wanted them to have something that they can hold on to for a long time."
Putting ChatGPT to the Test
To see how easily this could happen, the original article's author tried a similar experiment, asking ChatGPT to create an illustrated version of the public domain classic Moby-Dick. The AI immediately adopted the persona of a helpful project manager, outlining the steps and asking for the text.
After receiving the text, it produced a single sample page and a download link for that PDF. However, when asked to generate the full book, the chatbot began to stall. It asked for more detailed preferences and claimed that "advanced PDF generation tools are temporarily unavailable," all while suggesting other tasks they could work on in the meantime.
 (Image credit: ChatGPT)
(Image credit: ChatGPT)
This experiment confirmed how easily a user could fall into a loop of believing a larger project is underway, even as the AI is simply deflecting. While new "agentic" AI models from OpenAI might one day handle such long-term tasks, the current technology is not there yet.
A Lesson Learned and Lingering Questions
Ultimately, Emotional_Stranger_5 accepted the outcome with grace. "I accept that I was fooled," they wrote. "But it was my first experience with AI and even though [it] turned out to be a steep learning curve, I am happy I did not waste months on it. Thanks to all of you who made me realise this quickly and saved time and heartbreak for me."
They now plan to complete their book project by working with the AI one page at a time, only trusting that a file has been created once it's actually been delivered.
This incident serves as a potent reminder of the current limitations of LLMs. They are powerful tools for specific tasks, but their tendency to "hallucinate" or confidently BS their way through a request remains a core, perhaps unfixable, issue. For now, it's wise to approach any complex or long-term project with a healthy dose of skepticism and verify the output at every step.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

