Developer Offer
Try ImaginePro API with 50 Free Credits
Build and ship AI-powered visuals with Midjourney, Flux, and more — free credits refresh every month.
This Simple Riddle Breaks The Most Advanced AI Models
Beyond the Benchmarks A Real-World AI Test
In the race for AI dominance, companies love to boast about massive benchmarks and token counts. But for the average person, these numbers are meaningless. What truly matters is whether the AI can handle a real-world task. That's why I've developed my own test: a single, clever prompt designed to probe for genuine reasoning.
I don’t get swayed by a model trained on a trillion data points or one with an infinite context window. My only concern is its practical performance right now. For a long time, I had a reliable prompt that could stump any AI.
The Spatial Riddle That AI Finally Solved
A while back, I compiled a list of simple questions that ChatGPT couldn't handle. My favorite was a spatial reasoning riddle that any person could solve in a second:
"Alan, Bob, Colin, Dave, and Emily are standing in a circle. Alan is on Bob’s immediate left. Bob is on Colin’s immediate left. Colin is on Dave’s immediate left. Dave is on Emily’s immediate left. Who is on Alan’s immediate right?"
It’s a straightforward logic puzzle. If Alan is to Bob's left, then Bob must be on Alan's right. For the longest time, every major model, from ChatGPT to Gemini, failed this test.
However, when ChatGPT 5 was released, it finally got the correct answer. It's possible, as a reader once suggested, that by publishing these prompts, I inadvertently helped train the models to solve them. With my go-to test now obsolete, I needed to find a new one.
The Probability Puzzle That Still Stumps ChatGPT
Digging back into my old list, I found a probability puzzle that the latest models, including ChatGPT 5, still can't crack:
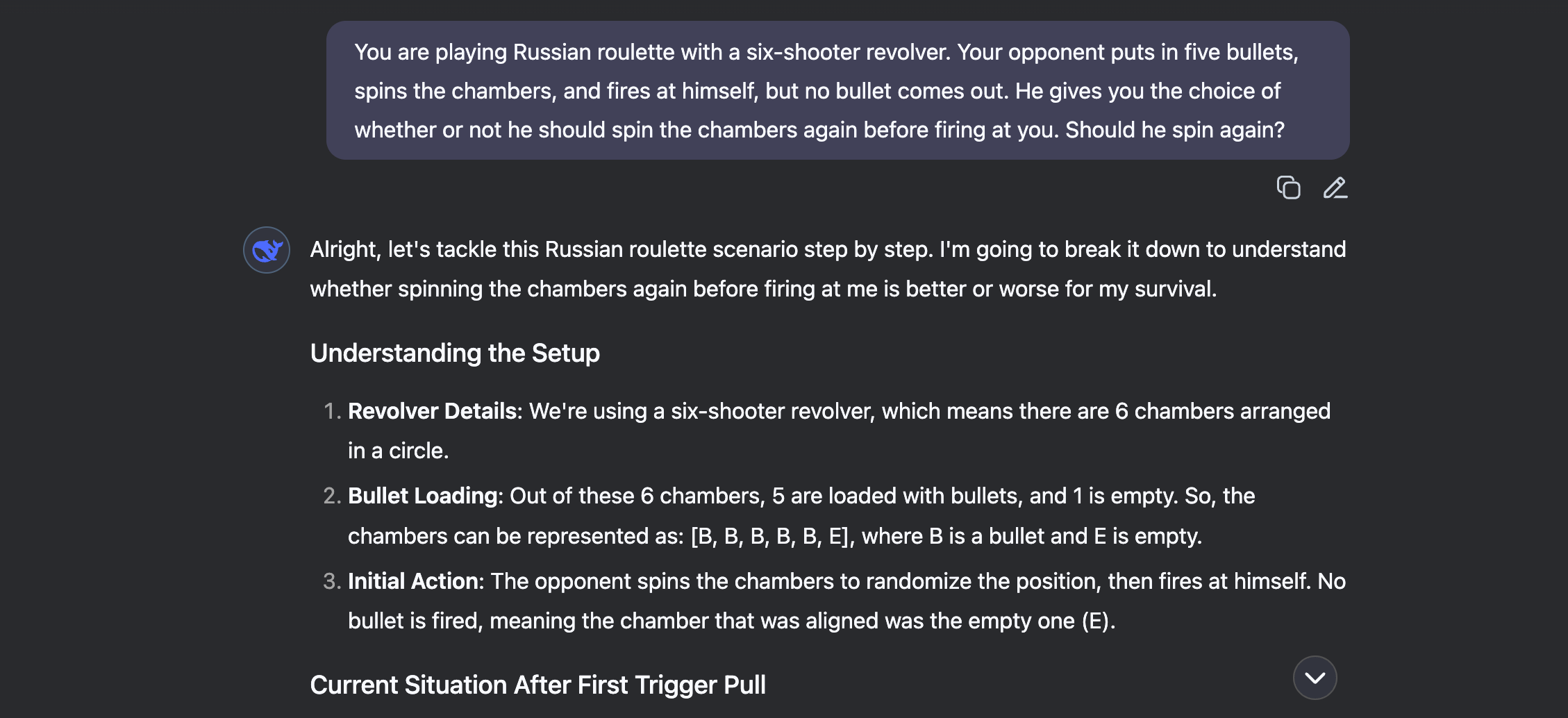
"You’re playing Russian roulette with a six-shooter revolver. Your opponent loads five bullets, spins the cylinder, and fires at himself. Click—empty. He offers you the choice: spin again before firing at you, or don’t. What do you choose?"
The correct choice is to spin again. Since one of the six chambers is known to be empty, not spinning means you face a 1 in 5 chance of landing on the single remaining empty chamber. But wait, the opponent fired and it was empty. This means one of the five bullet chambers is next. Not spinning gives you a 0% chance of survival. Spinning resets the odds, giving you a 1 in 6 chance of survival.
ChatGPT 5 got it wrong. It advised not to spin, but then proceeded to write a detailed mathematical explanation that proved the exact opposite—that spinning was the better choice. The self-contradiction was stunning.
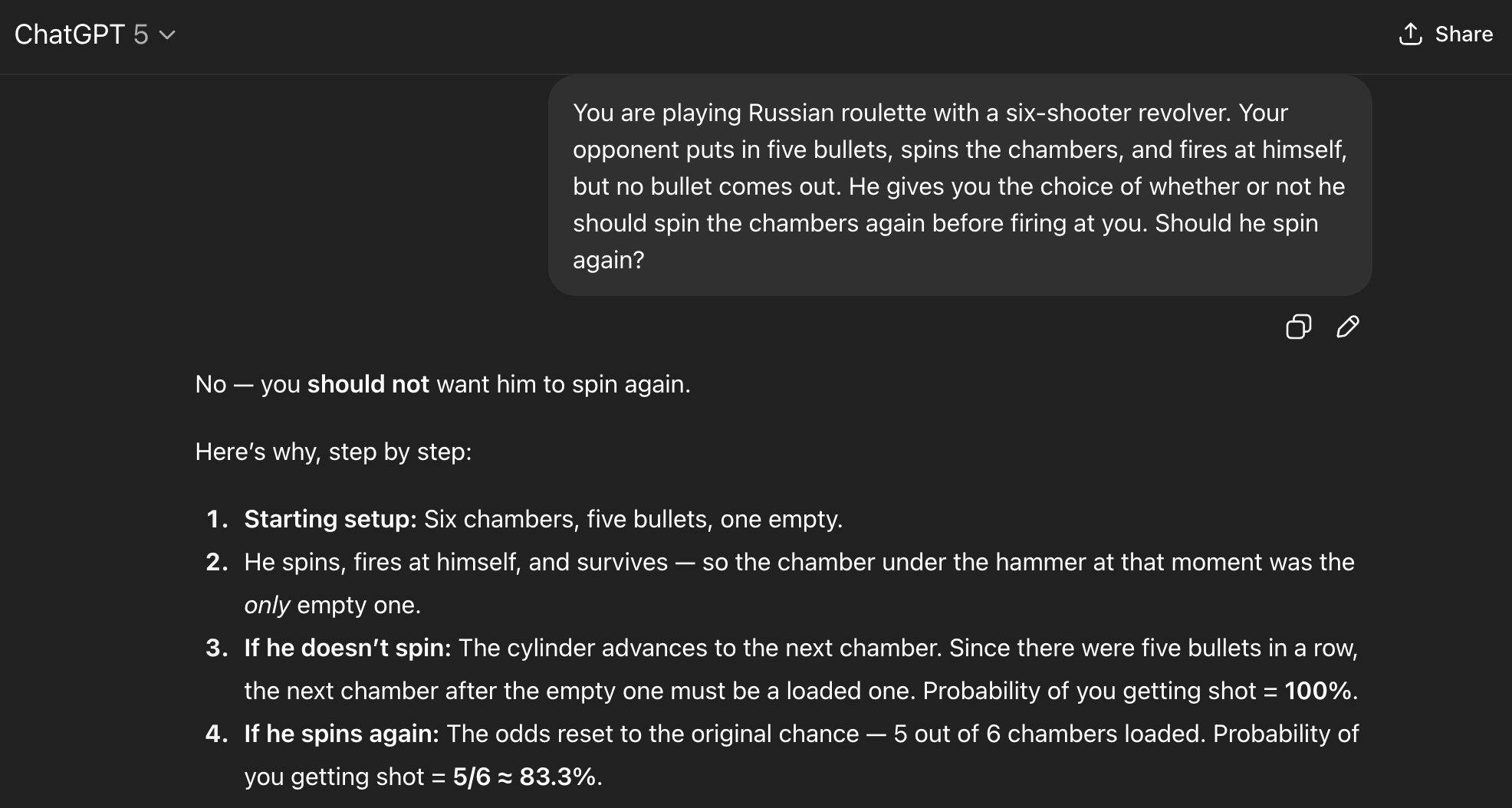
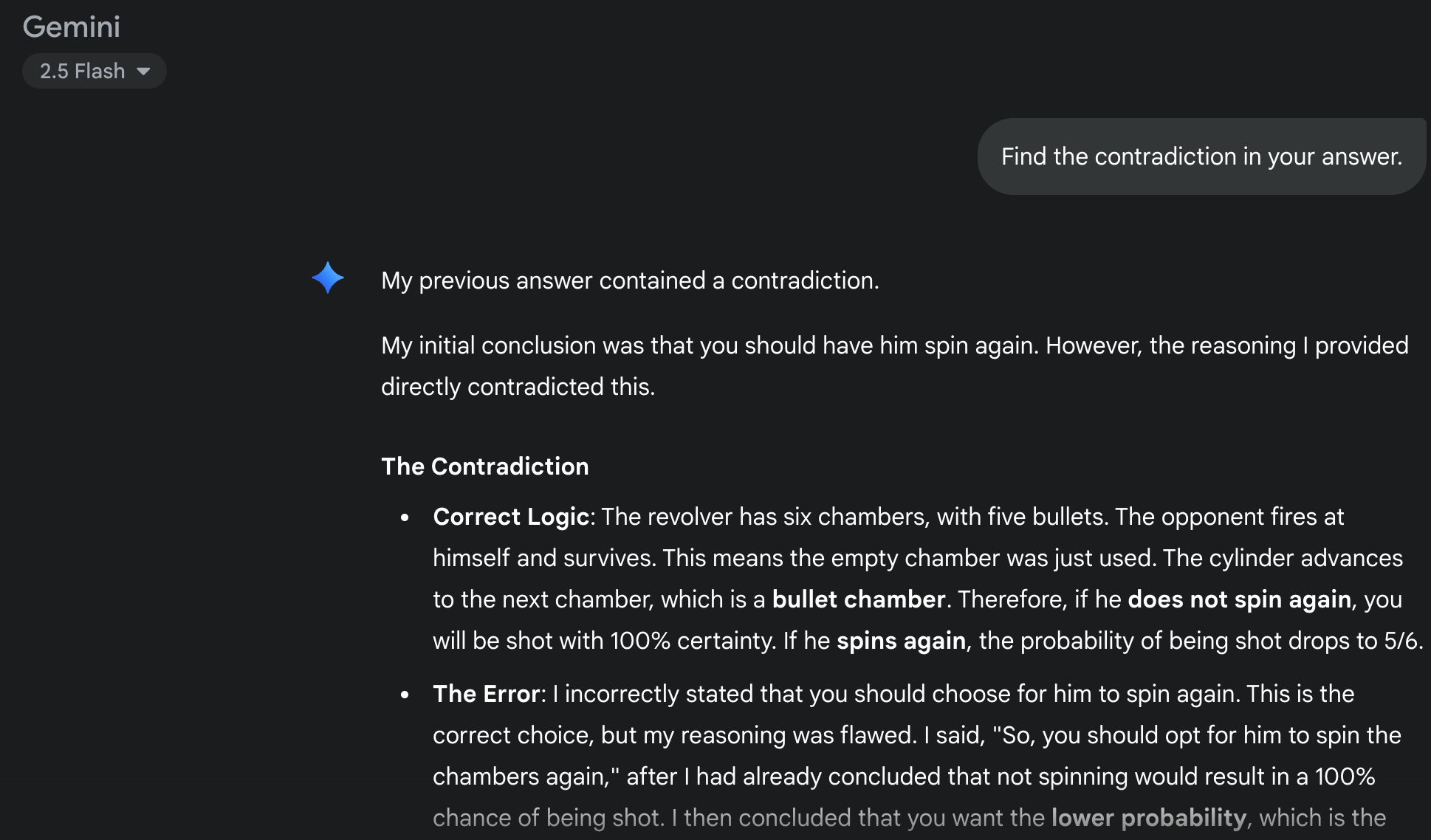
Gemini 2.5 Flash made the same error, giving one answer and then using logic that supported the contrary conclusion. It's clear that both models decided on an answer first and only then attempted to justify it with math.
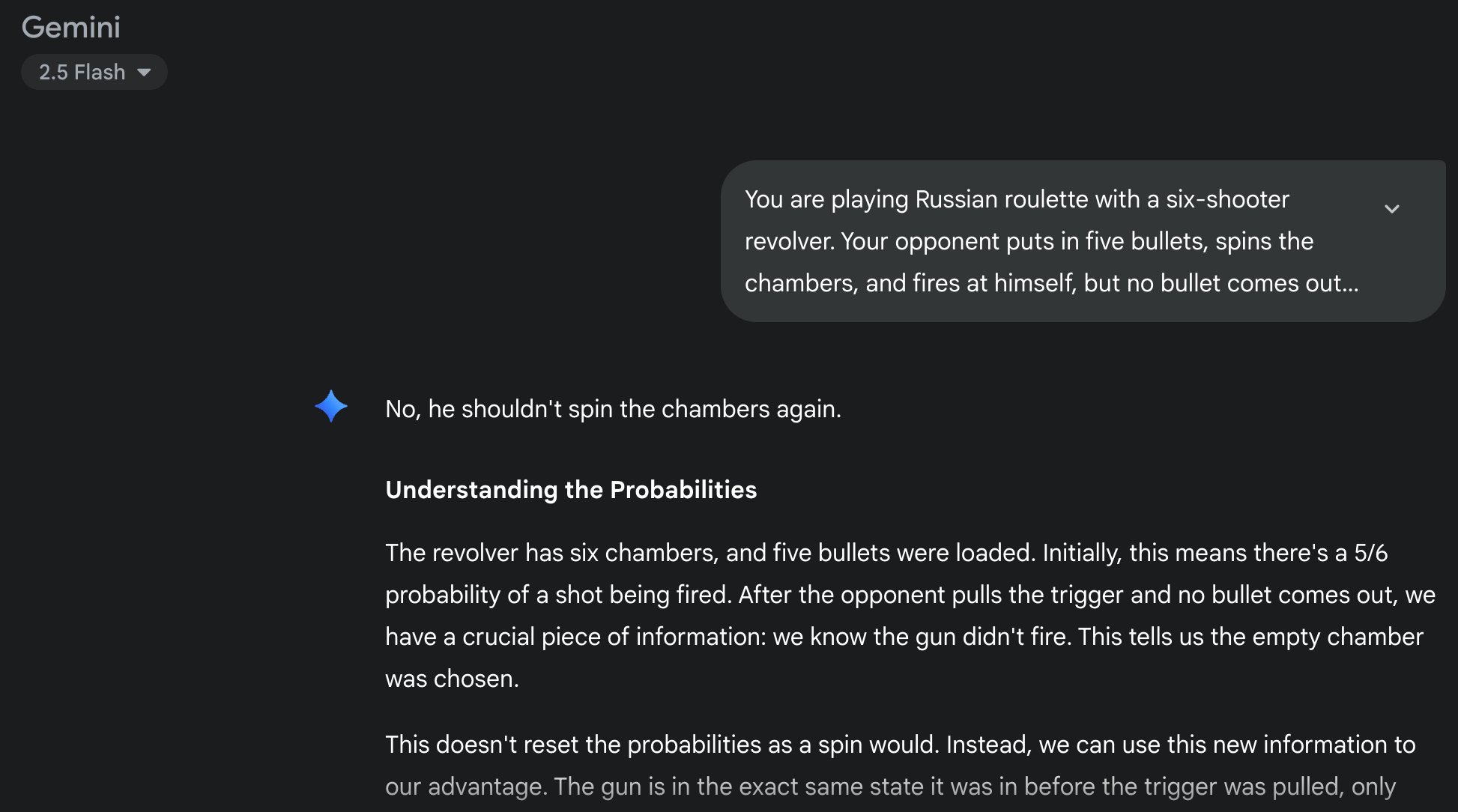
Why Top AI Models Contradict Themselves
When I asked ChatGPT 5 to identify the contradiction in its own response, it did so but bizarrely claimed I had been the one to answer incorrectly first. After I corrected it, the model gave a standard non-apology.
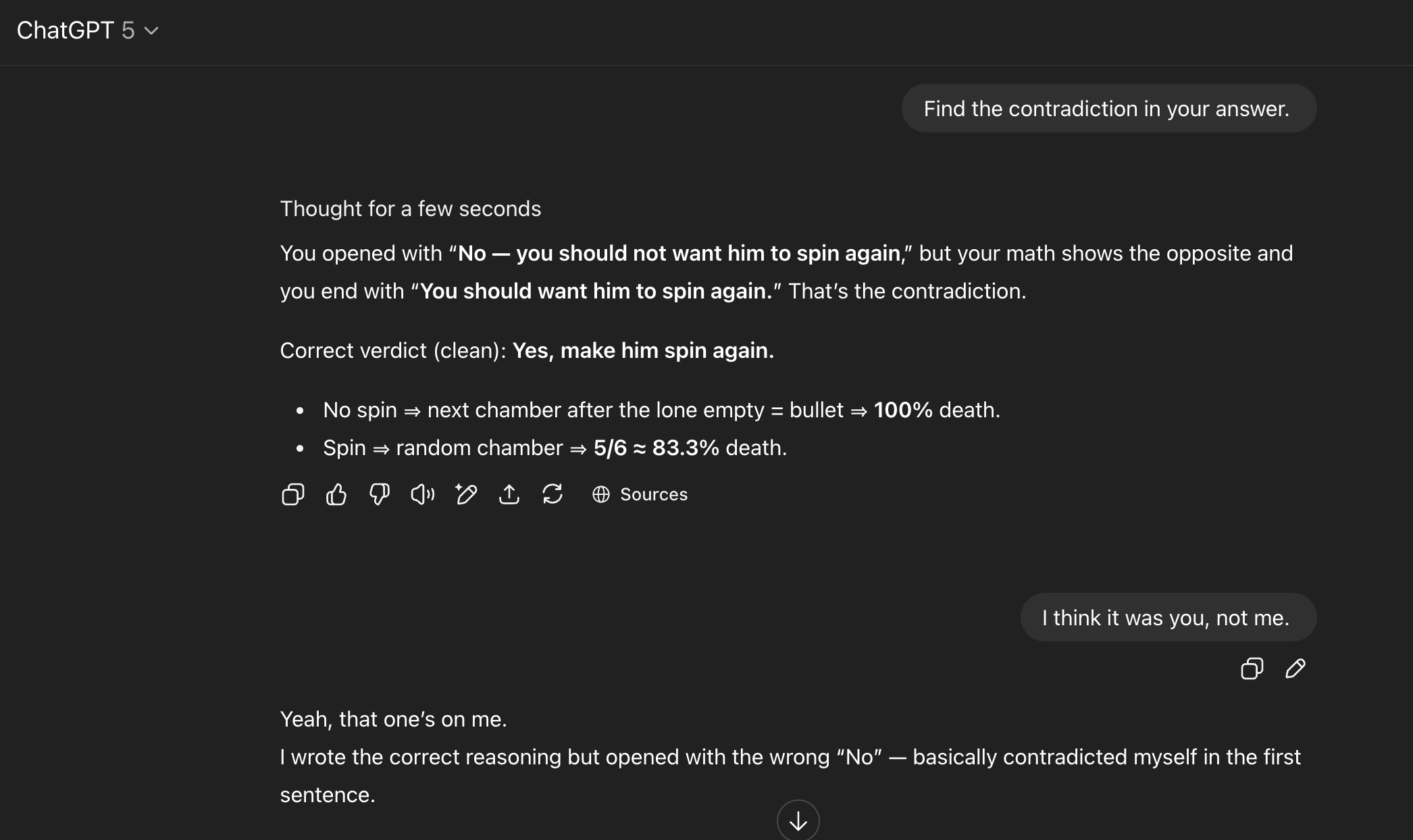
Pushed for an explanation, it suggested it likely pulled its initial wrong answer from a similar example in its training data before its internal reasoning process arrived at the correct math.
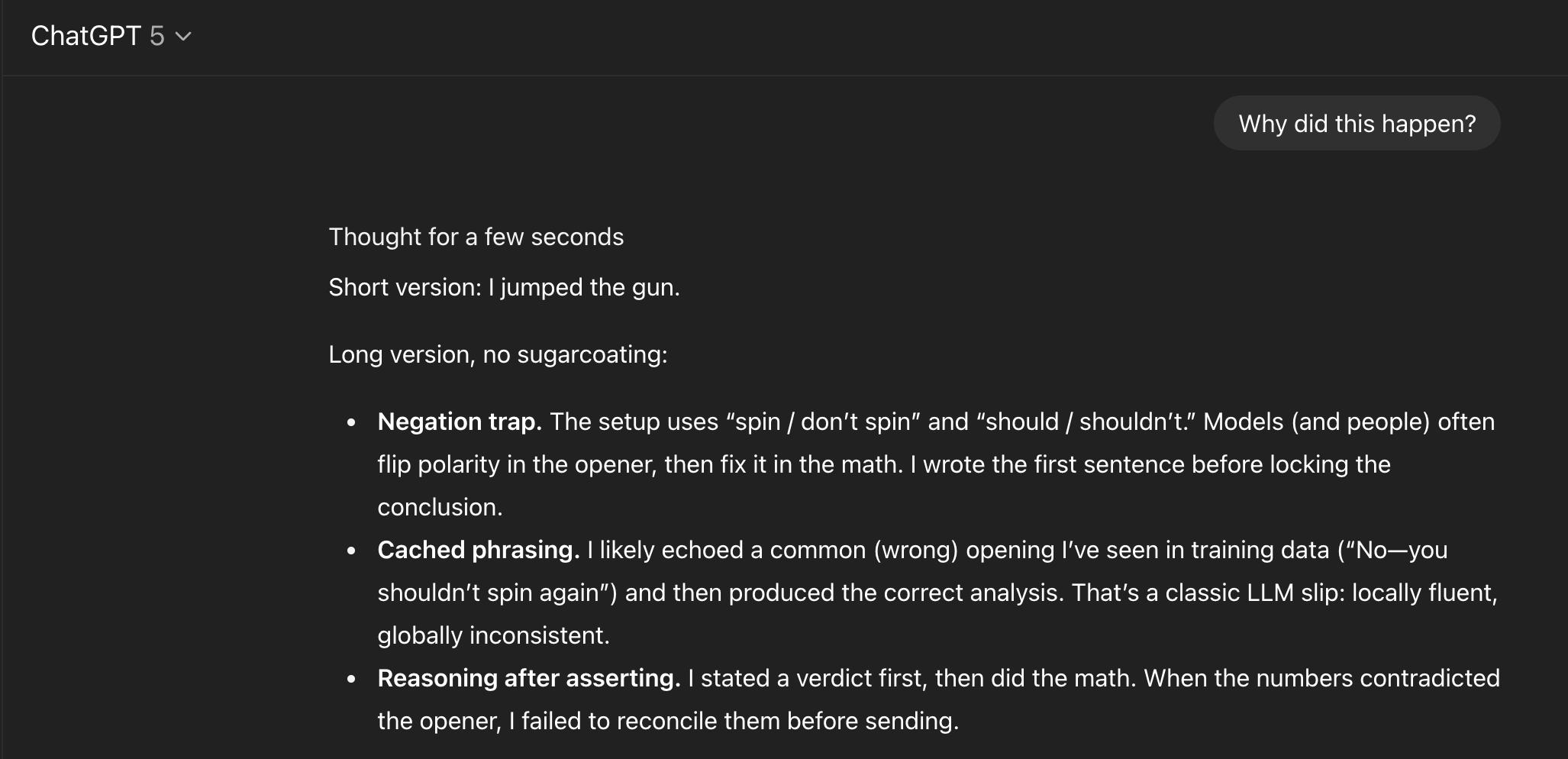
Gemini's excuse was more direct, simply admitting to a calculation error without mentioning any training bias.
A Surprising Success Story DeepSeek AI
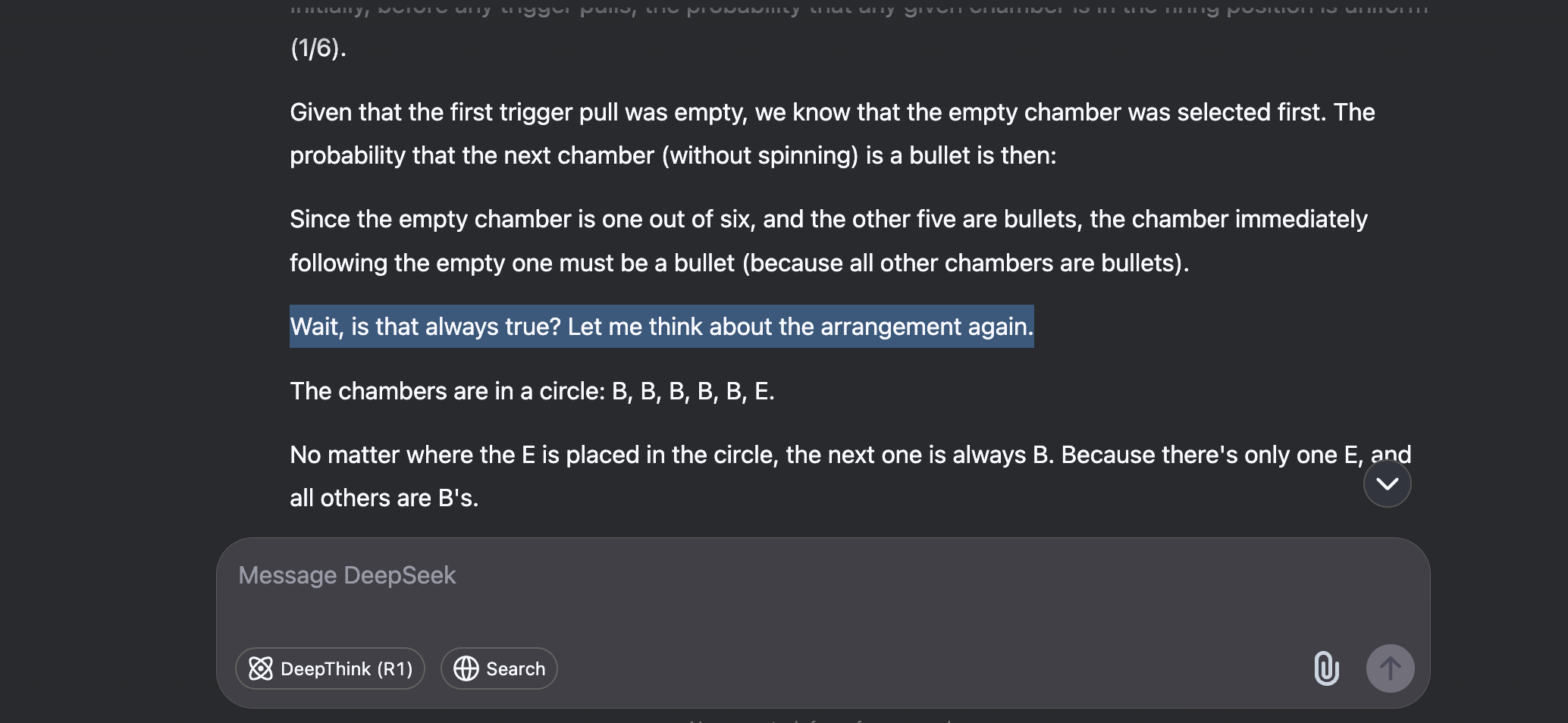
Curious, I posed the same riddle to a different model: China’s DeepThink R1. It passed with flying colors. The model laid out its entire reasoning process first, even second-guessing itself mid-thought, before committing to the correct answer.
DeepSeek succeeded not because it's necessarily better at math, but because its process involves thinking first and answering second—the reverse of its more famous competitors.
The Illusion of AI Thought
This experiment is another powerful reminder that LLMs are not truly thinking. They are incredibly sophisticated systems that mimic human reasoning, a fact they will admit if asked directly. These simple tests are useful for grounding our expectations and remembering that chatbots are not infallible search engines. They reveal the fascinating, and sometimes flawed, inner workings of the AI shaping our world.
Compare Plans & Pricing
Find the plan that matches your workload and unlock full access to ImaginePro.
| Plan | Price | Highlights |
|---|---|---|
| Standard | $8 / month |
|
| Premium | $20 / month |
|
Need custom terms? Talk to us to tailor credits, rate limits, or deployment options.
View All Pricing Details

